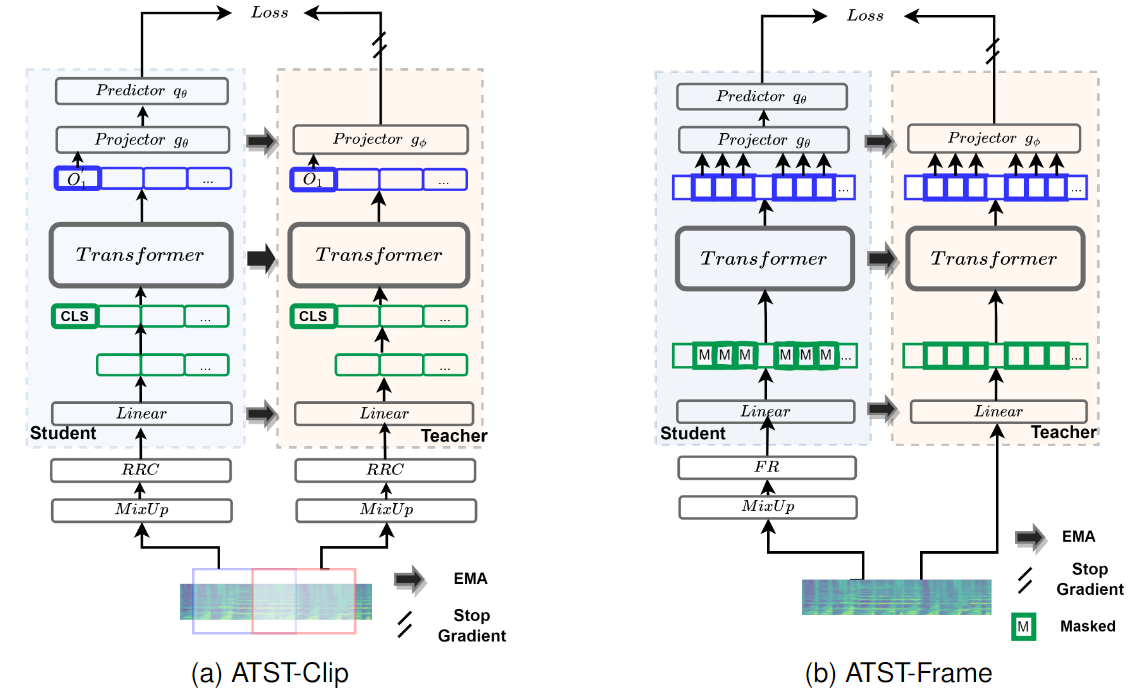
[Accepted by TASLP] We introduce a novel Self-Supervised Learning model for audio processing, named ATST-Frame. Thorough experiments on clip/frame-level downstream tasks are implemented. SOTA performances are obtained on most task.
Authors
Xian Li; Nian Shao; Xiaofei Li
Abstract
In recent years, self-supervised learning (SSL) has emerged as a popular approach for learning audio representations. The ultimate goal of audio self-supervised pre-training is to transfer knowledge to downstream audio tasks, generally including clip-level and frame-level tasks. Clip-level tasks classify the scene or sound of an entire audio clip, e.g. audio tagging, instrument recognition, etc. While frame-level tasks detect event-level timestamps from an audio clip, e.g. sound event detection, speaker diarization, etc. Prior studies primarily evaluate on clip-level downstream tasks. Frame-level tasks are important for fine-grained acoustic scene/event understanding, and are generally more challenging than clip-level tasks. In order to tackle both clip-level and frame-level tasks, this paper proposes two self-supervised audio representation learning methods: ATST-Clip and ATST-Frame, responsible for learning clip-level and frame-level representations, respectively. ATST stands for Audio Teacher-Student Transformer, which means both methods use a transformer encoder and a teacher-student training scheme.Experimental results show that our ATST-Frame model obtains state-of-the-art (SOTA) performance on most of the clip-level and frame-level downstream tasks. Especially, it outperforms other models by a large margin on the frame-level sound event detection task. In addition, the performance can be further improved by combining the two models through knowledge distillation.
URL
https://arxiv.org/pdf/2306.04186.pdf
Code
Training Overflow