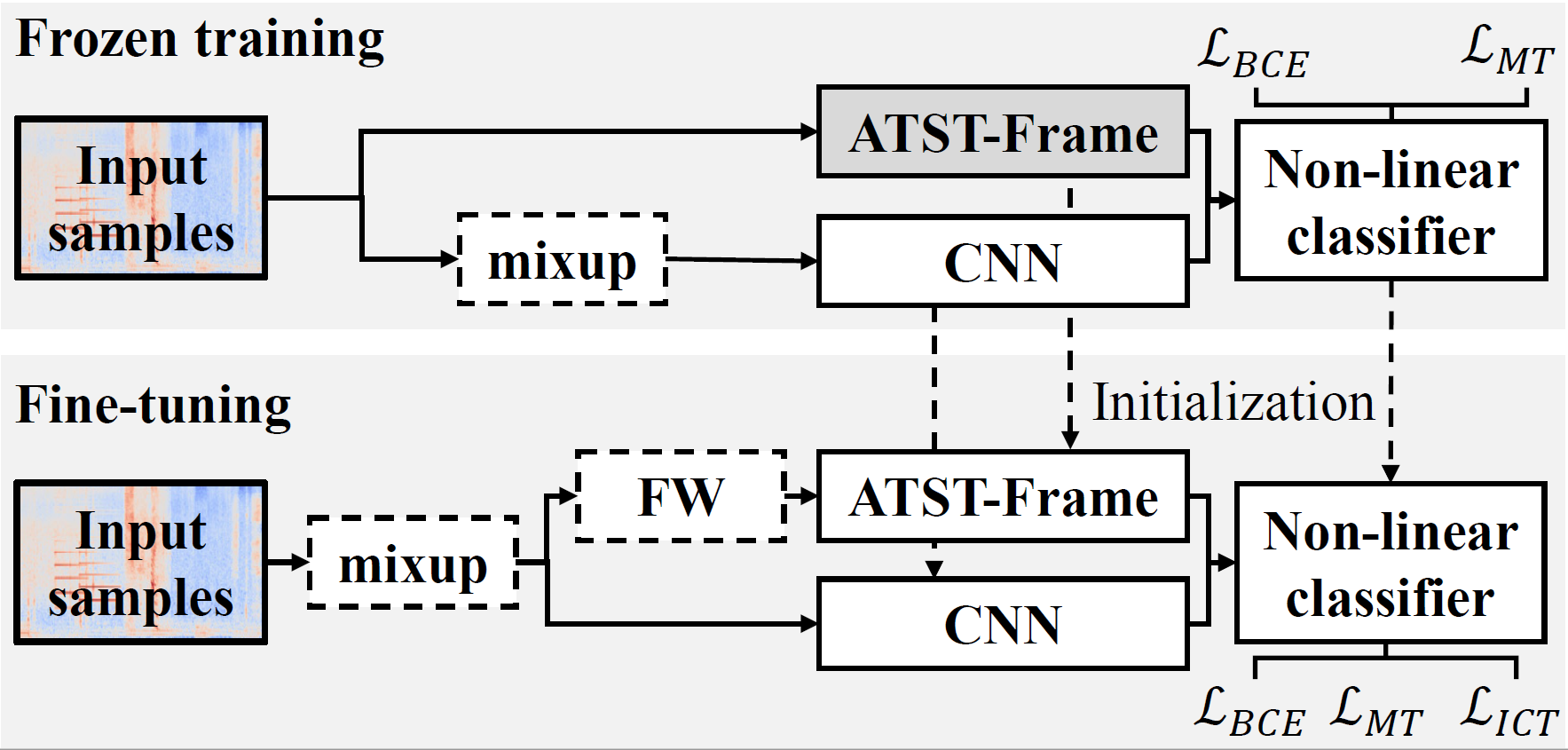
Fine-tune the Pretrained ATST Model for Sound Event Detection
Fine-tuning ATST-Frame for sound event detection and achieving new SOTA results on DESED development set.
Fine-tuning ATST-Frame for sound event detection and achieving new SOTA results on DESED development set.
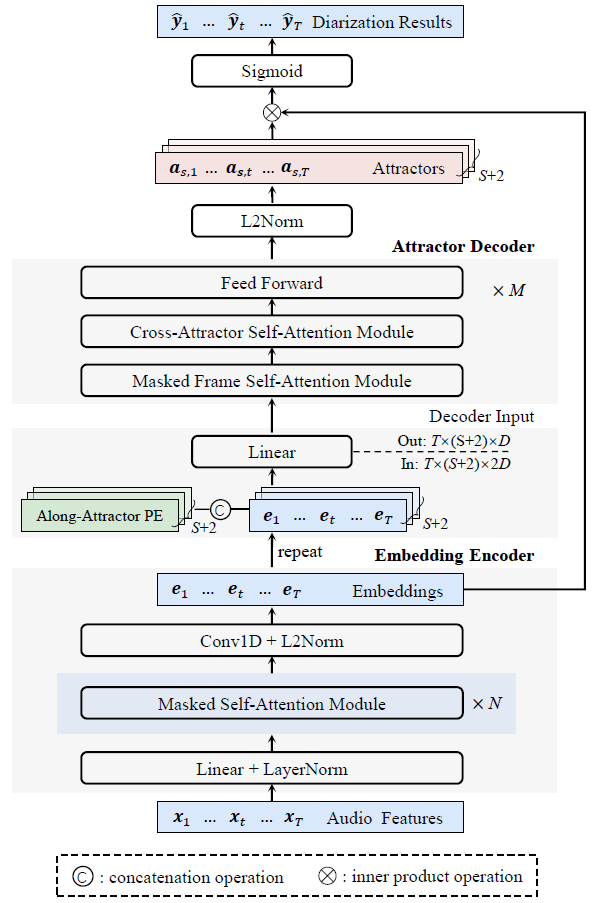
A low-latency online EEND framework with causal encoding and non-autoregressive attractor decoding.
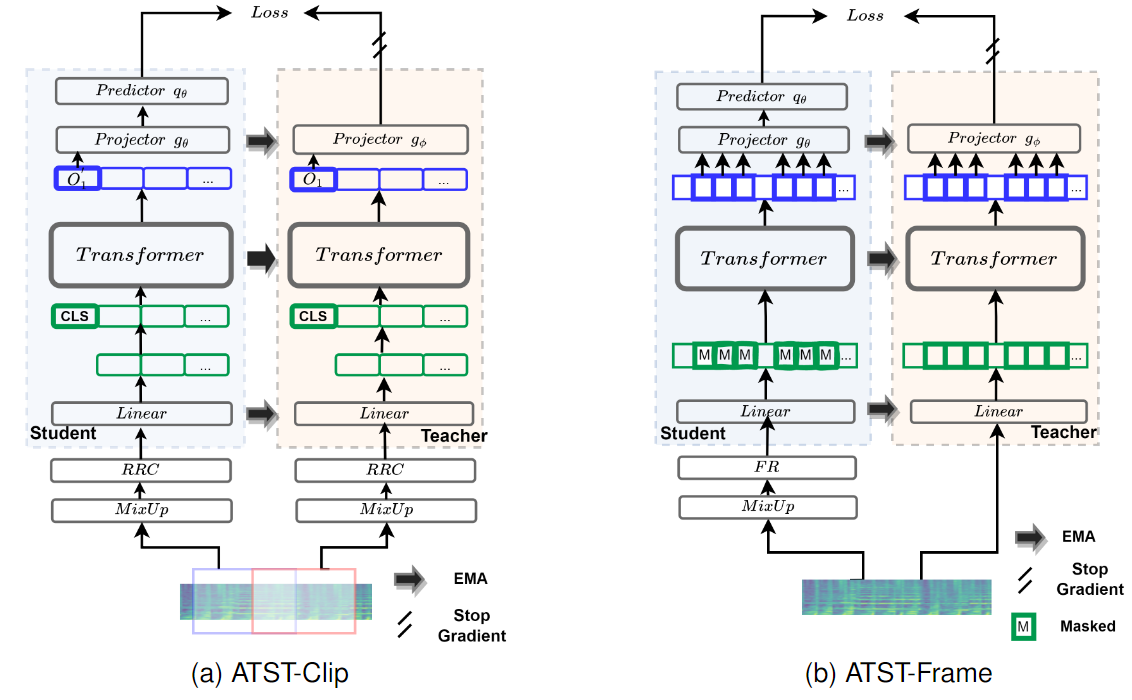
ATST-Clip and ATST-Frame for unified clip-level and frame-level tasks with broad SOTA gains.
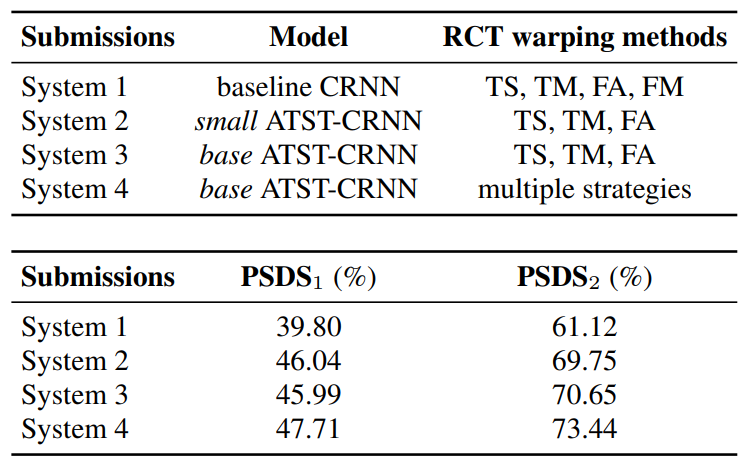
Integrating ATST-Clip with RCT-CRNN, ranking 4th in DCASE 2022 Task 4 single-model setting.
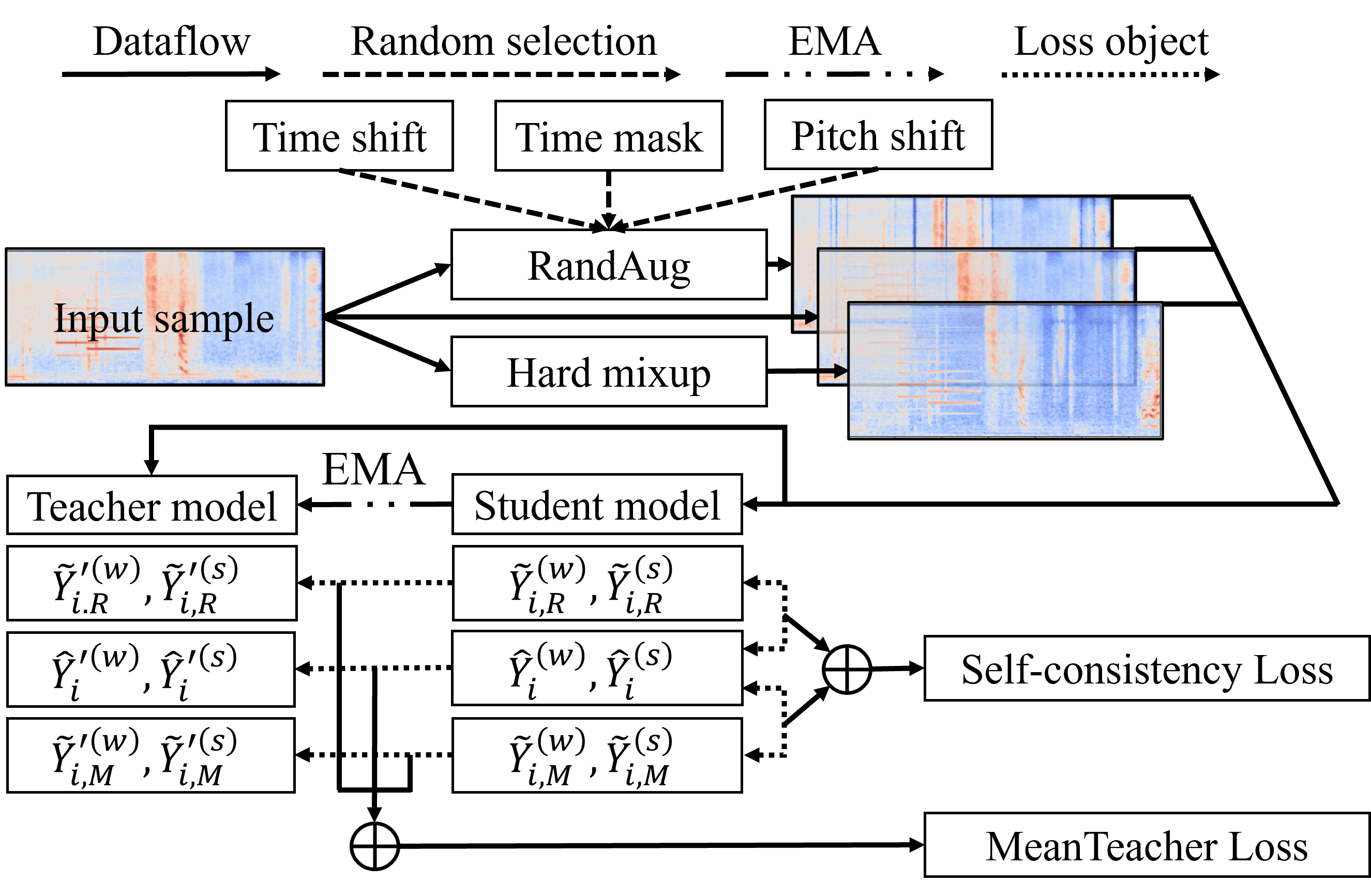
Random Consistency Training for SED with clear improvements across CRNN-based systems.
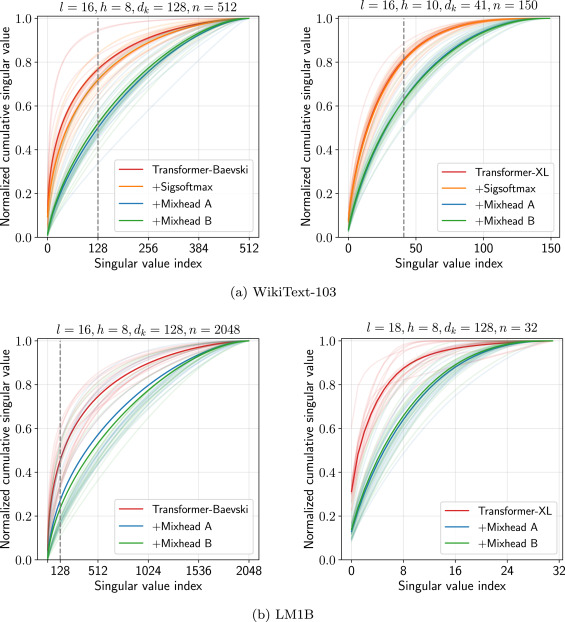
Learnable head-mixing to mitigate low-rank bottlenecks in attention for language modeling and GLUE.