[DCASE 2022 tech. report] The technical report for our submitted system in the DCASE 2022 challenge, task 4. We integrate the pretrained ATST-Clip with a CRNN model and obtain 4th place in the challenge (single model + using extra dataset).
Authors
Nian Shao; Xian Li; Xiaofei Li
Abstract
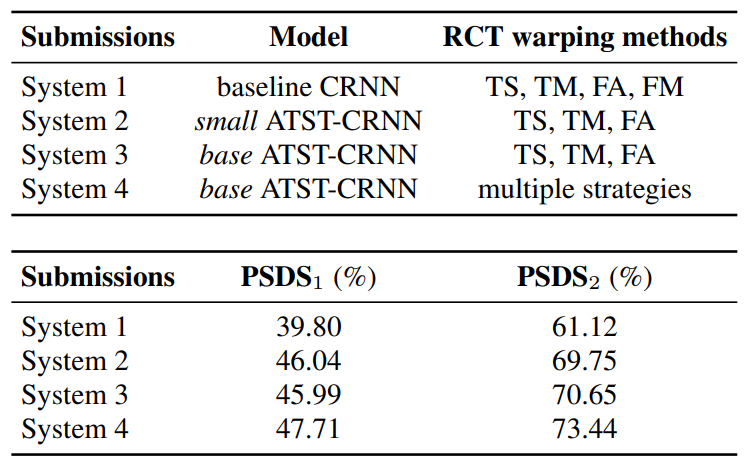
In this report, we present our methods proposed for participating the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 4: Sound Event Detection in Domestic Environments. The proposed methods integrate a semisupervised sound event detection model (called random consistency training, RCT) trained with the relatively small official dataset of the challenge, and a self-supervised model (called audio teacherstudent transformer, ATST) trained with the very large AudioSet. RCT uses the baseline convolutional recurrent neural network (CRNN) of the challenge, and adopts a newly proposed semisupervised learning scheme based on random data augmentation and a self-consistency loss. To integrate ATST into RCT, the feature extracted by ATST is concatenated with the feature extracted by the convolutional layers of RCT, and then fed to the RNN layers of RCT. It is found that these two types of feature are complementary and the performance can be largely improved by combining them. In development, RCT individually achieves 39.80% and 61.12% of PSDS1 and PSDS2, respectively, which are improved to 45.99% and 70.65% by integrating the ATST feature, and further to 47.71% and 73.44% by ensembling five models with different training configurations.
URL
https://dcase.community/documents/challenge2022/technical_reports/DCASE2022_Shao_35_t4.pdf
Code
Main Results