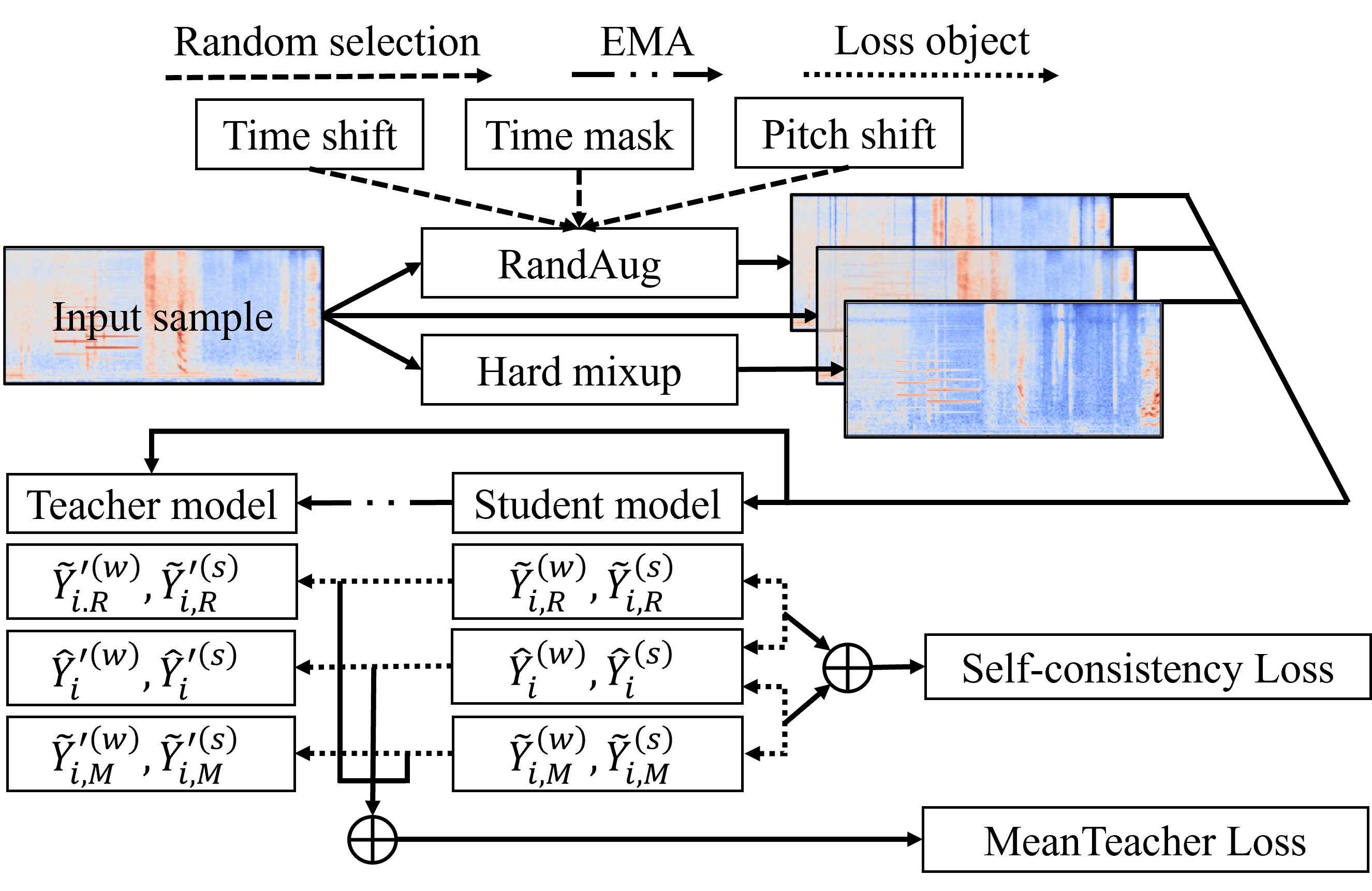
[Accepcted by Interspeech 2022] We introduce a semi-supervised learning method for SED and test its performance over DESED dataset. We obtain SOTA performance in all CRNN-based models, surpassing SCT and ICT methods.
Authors
Nian Shao; Erfan Loweimi; Xiaofei Li
Abstract
Sound event detection (SED), as a core module of acoustic environmental analysis, suffers from the problem of data deficiency. The integration of semi-supervised learning (SSL) largely mitigates such problem. This paper researches on several core modules of SSL, and introduces a random consistency training (RCT) strategy. First, a hard mixup data augmentation is proposed to account for the additive property of sounds. Second, a random augmentation scheme is applied to stochastically combine different types of data augmentation methods with high flexibility. Third, a self-consistency loss is proposed to be fused with the teacher-student model, aiming at stabilizing the training. Performance-wise, the proposed modules outperform their respective competitors, and as a whole the proposed SED strategies achieve 44.0% and 67.1% in terms of the PSDS_1 and PSDS_2 metrics proposed by the DCASE challenge, which notably outperforms other widely-used alternatives.
URL
https://www.isca-speech.org/archive/interspeech_2022/shao22_interspeech.html
Code
Strategy overflow