[Accepted by ICASSP 2024] We introduce a fine-tuning method for the pretrained model (ATST-Frame) integrated in the SED system. And we obtain new SOTA performances on the DESED development dataset.
Authors
Nian Shao; Xian Li; Xiaofei Li
Abstract
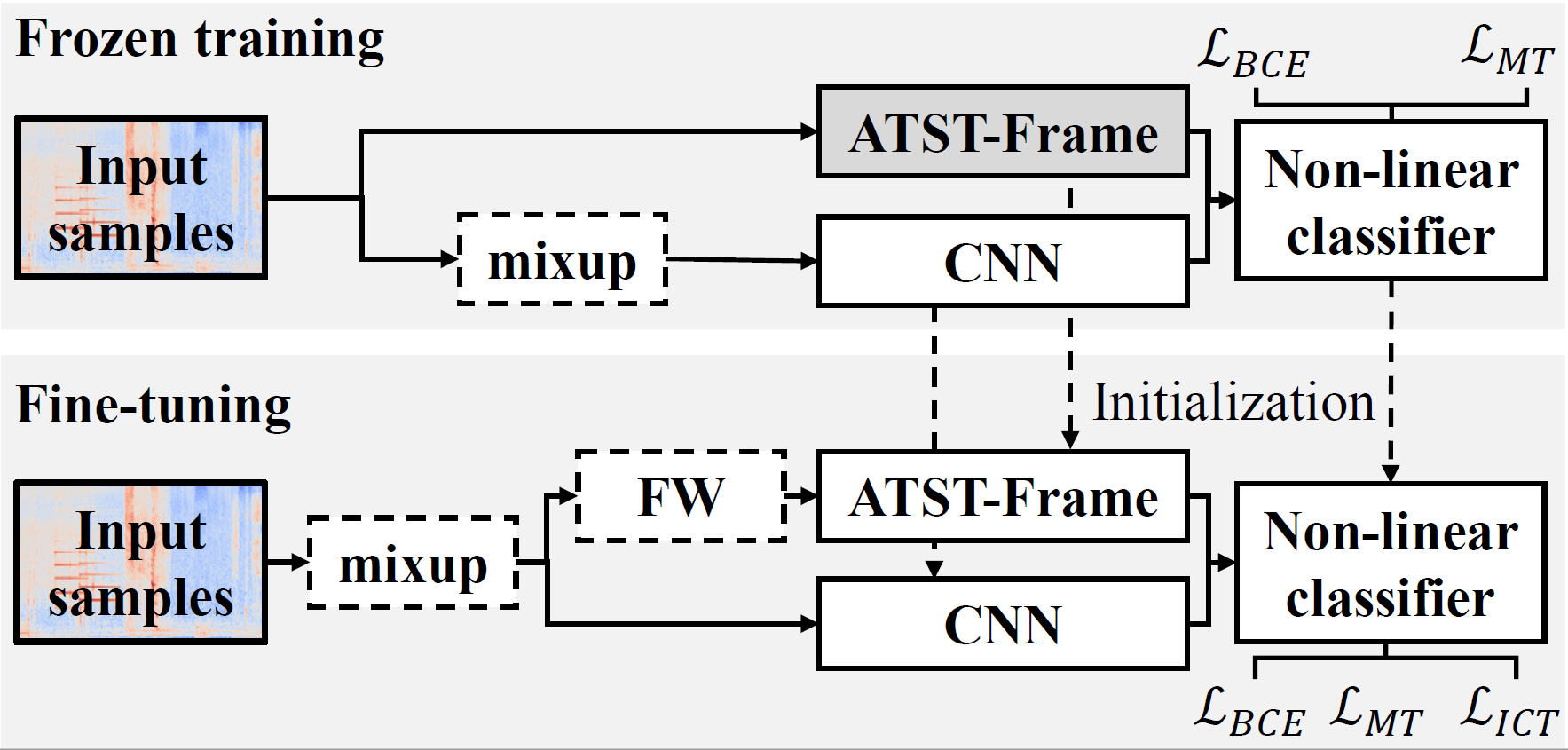
Sound event detection (SED) often suffers from the data deficiency problem. The recent baseline system in the DCASE2023 challenge task 4 leverages the large pretrained self-supervised learning (SelfSL) models to mitigate such restriction, where the pretrained models help to produce more discriminative features for SED. However , the pretrained models are regarded as a frozen feature extractor in the challenge baseline system and most of the challenge submissions , and fine-tuning of the pretrained models has been rarely studied. In this work, we study the fine-tuning method of the pre-trained models for SED. We first introduce ATST-Frame, our newly proposed SelfSL model, to the SED system. ATST-Frame was especially designed for learning frame-level representations of audio signals and obtained state-of-the-art (SOTA) performances on a series of downstream tasks. We then propose a fine-tuning method for ATST-Frame using both (in-domain) unlabelled and labelled SED data. Our experiments show that, the proposed method overcomes the overfitting problem when fine-tuning the large pretrained network , and our SED system obtains new SOTA results of 0.587/0.812 PSDS1/PSDS2 scores on the DCASE challenge task 4 dataset.
URL
https://arxiv.org/pdf/2309.08153v1.pdf
Code
Strategy Overflow